안녕하세요, 하이스트레인저 테크리더 고수진입니다.
최근 GPT-5가 발표되었고, 개발자들은 CoPilot, Claude 등 다양한 AI를 활용해 작업을 하고 있습니다. 저희 INSIGHT FLOW도 최근 고도화를 진행하면서 LLM 모델 및 다양한 멀티모달 AI들을 적용하고 있습니다.
LLM 모델 하면 가장 먼저 떠오르는 것이 바로 생성형 AI 모델입니다. 그래서 이번 달에는 생성 LLM 모델에 대해 작성해 보려 합니다. AI 모델은 매일 쏟아져 나오지만, 각 모델은 비슷하면서도 다른 특징을 가지고 있습니다. 2024년부터 2025년까지의 생성형 LLM 모델에 대해 공유하고자 합니다.
생성형 AI, LLM 기술 방향
2023년부터 2025년은 생성형 LLM이 실험실을 벗어나 현업에서 가치를 입증한 전환기였습니다. OpenAI GPT-5의 통합 추론, Google Gemini의 네이티브 멀티모달 처리, Meta Llama 4의 10M 토큰 컨텍스트, 국내 HyperCLOVA X의 한국어 특화 성능은 기술의 고도화를 보여줍니다. 특히, 기업들은 LLM 도입을 통해 평균 3.7배의 ROI를 기록했다는 보고가 이어지고 있습니다.
중요한 것은 단순히 많이 쓰는 모델이 아니라, 아키텍처와 동작 원리를 이해한 뒤 적재적소에 적용하는 일이라고 생각합니다. 원리를 알고 설계하고 운영하면 활용 가치는 배가 됩니다.
LLM의 기술적 원리와 핵심 메커니즘
텍스트 생성의 마법: 다음 토큰 예측
생성형 LLM의 핵심은 다음에 올 가장 적절한 단어(토큰)를 예측하는 것입니다.
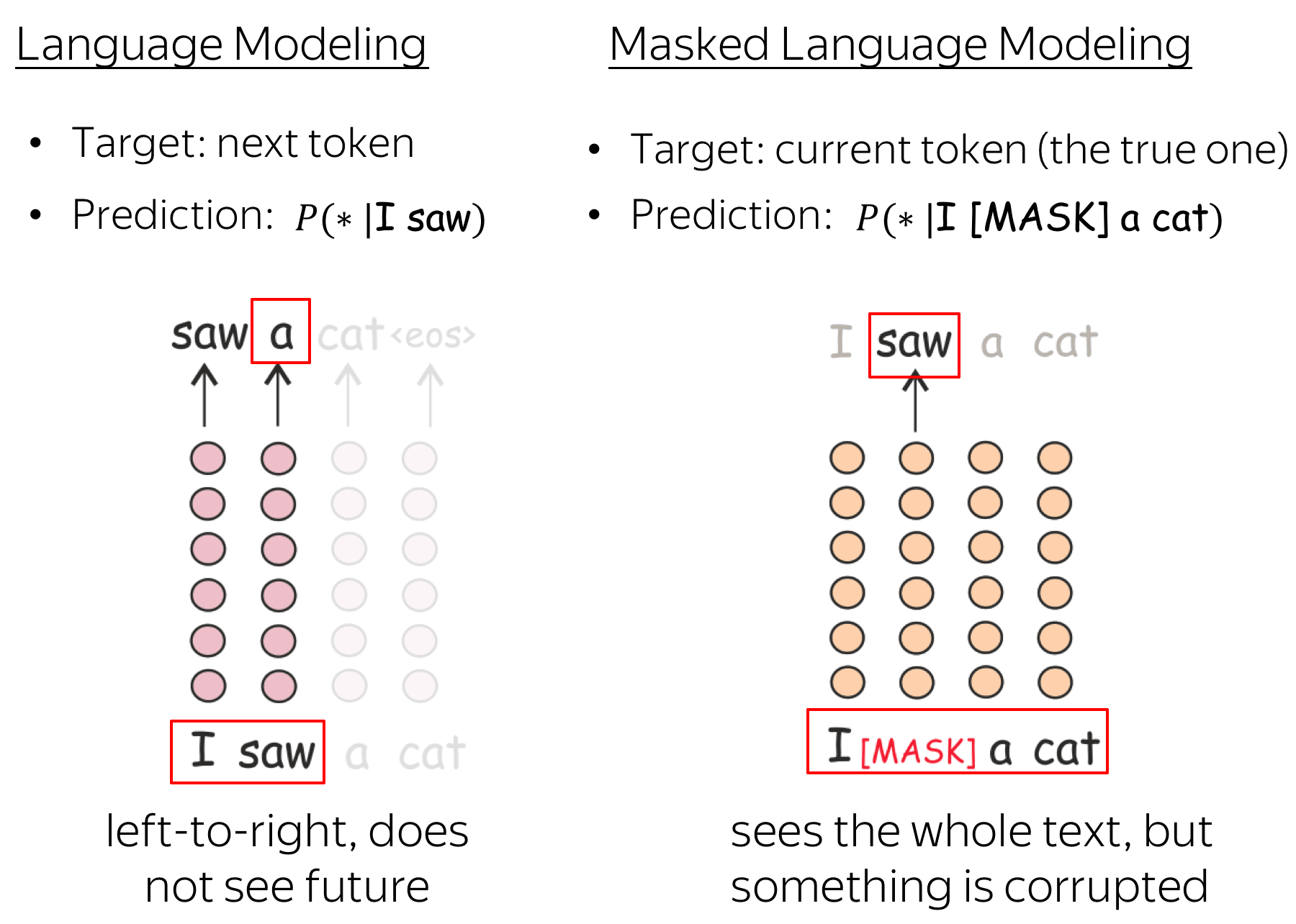
사용자가 “오늘 날씨가“라고 입력하면, 모델은 다음 토큰 후보(예: “좋네요”, “어때요”, “화창해요” 등)에 확률을 매기고 규칙에 따라 하나를 선택합니다. 이 과정을 반복해 문장과 문단이 생성됩니다.
실제 생성 절차는 다음과 같습니다.
- 입력 문장을 토큰으로 분해합니다.
- 각 토큰을 임베딩 벡터로 변환합니다.
- 트랜스포머가 토큰 간 의존성을 계산해 다음 토큰의 확률 분포를 만듭니다.
- 샘플링 규칙(temperature, top-p/top-k 등)에 따라 다음 토큰을 선택합니다.
트랜스포머 아키텍처
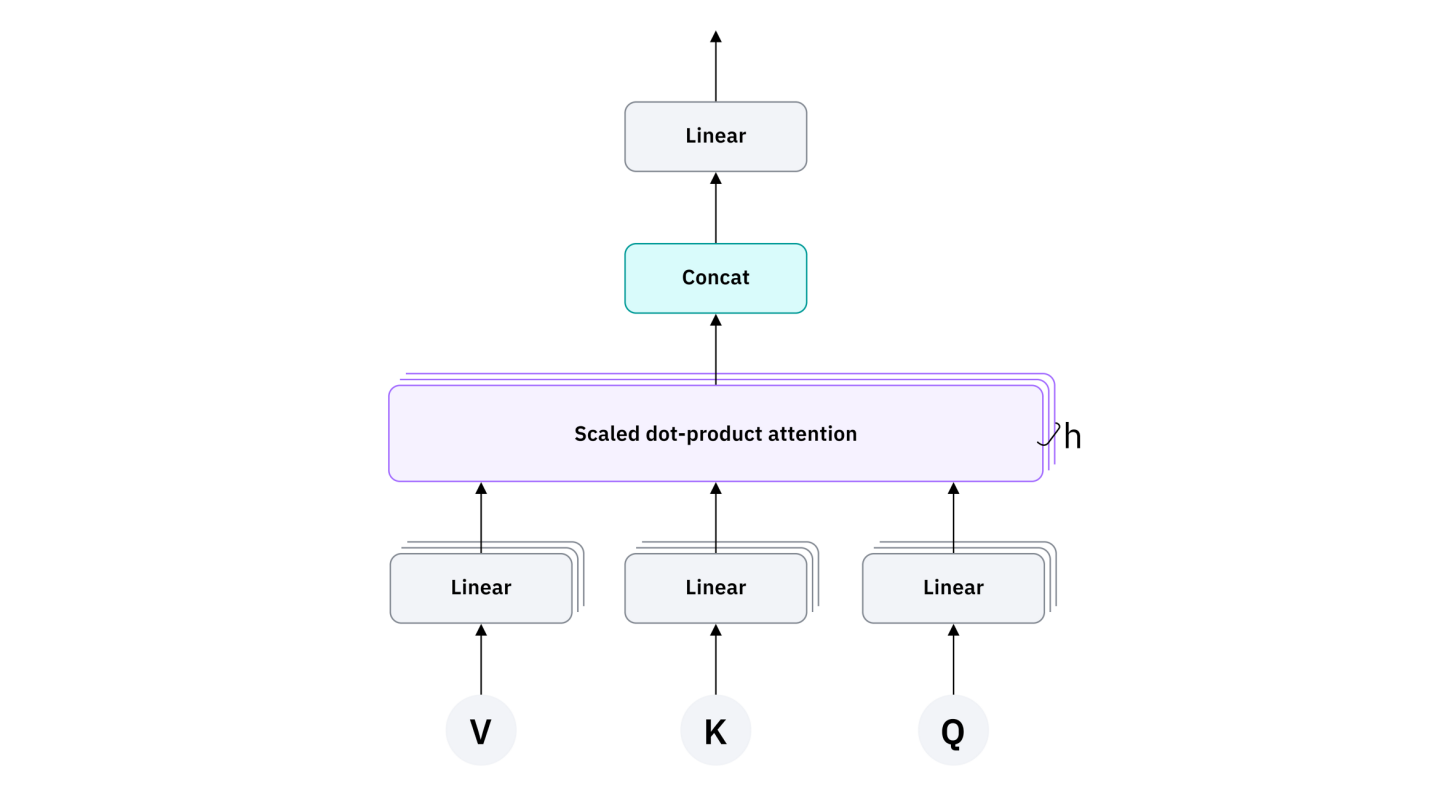
어텐션은 모델이 입력 데이터에서 가장 중요한 부분에 집중할 수 있도록 도와주는 기법입니다. 이는 트랜스포머 모델의 핵심이며, 2017년 구글이 발표한 논문 “Attention Is All You Need“에서 소개되었습니다. 트랜스포머는 기존 신경망의 한계를 해결하며 병렬 처리를 가능하게 했고, 긴 문장의 의존 관계를 더 효과적으로 분석할 수 있게 되었습니다.
3단계 훈련 파이프라인의 진화
LLM 훈련 과정은 3단계로 구분됩니다.
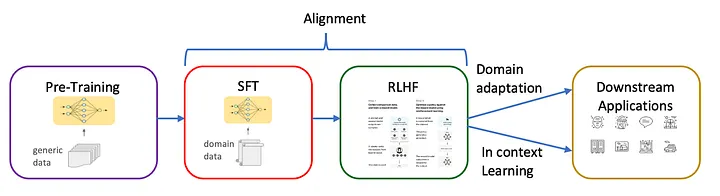
- 사전 훈련: 수조 개의 토큰으로 언어의 기본 패턴을 학습합니다.
- 지도학습 미세조정(SFT): 미리 학습된 모델을 고품질 데이터셋으로 대화 능력을 개발합니다.
- 인간피드백 강화학습(RLHF): 모델이 인간의 선호도에 맞는 응답을 생성하도록 최적화합니다.
최근에는 Constitutional AI와 DPO(Direct Preference Optimization) 같은 새로운 정렬 기법이 등장하고 있습니다.
모델 크기와 성능의 관계
스케일링 법칙에 따르면 모델 크기, 훈련 데이터, 계산량이 증가할수록 성능이 향상됩니다.
- 7B 모델: 약 14GB 메모리가 필요해 로컬 실행이 가능합니다.
- 70B 모델: 140GB 메모리로 전문 GPU가 필요합니다.
- 175B+ 모델: 클라우드 서비스를 통한 접근이 현실적입니다.
2025년 주요 LLM 모델 완전 분석
GPT 시리즈: 비추론과 고급 추론
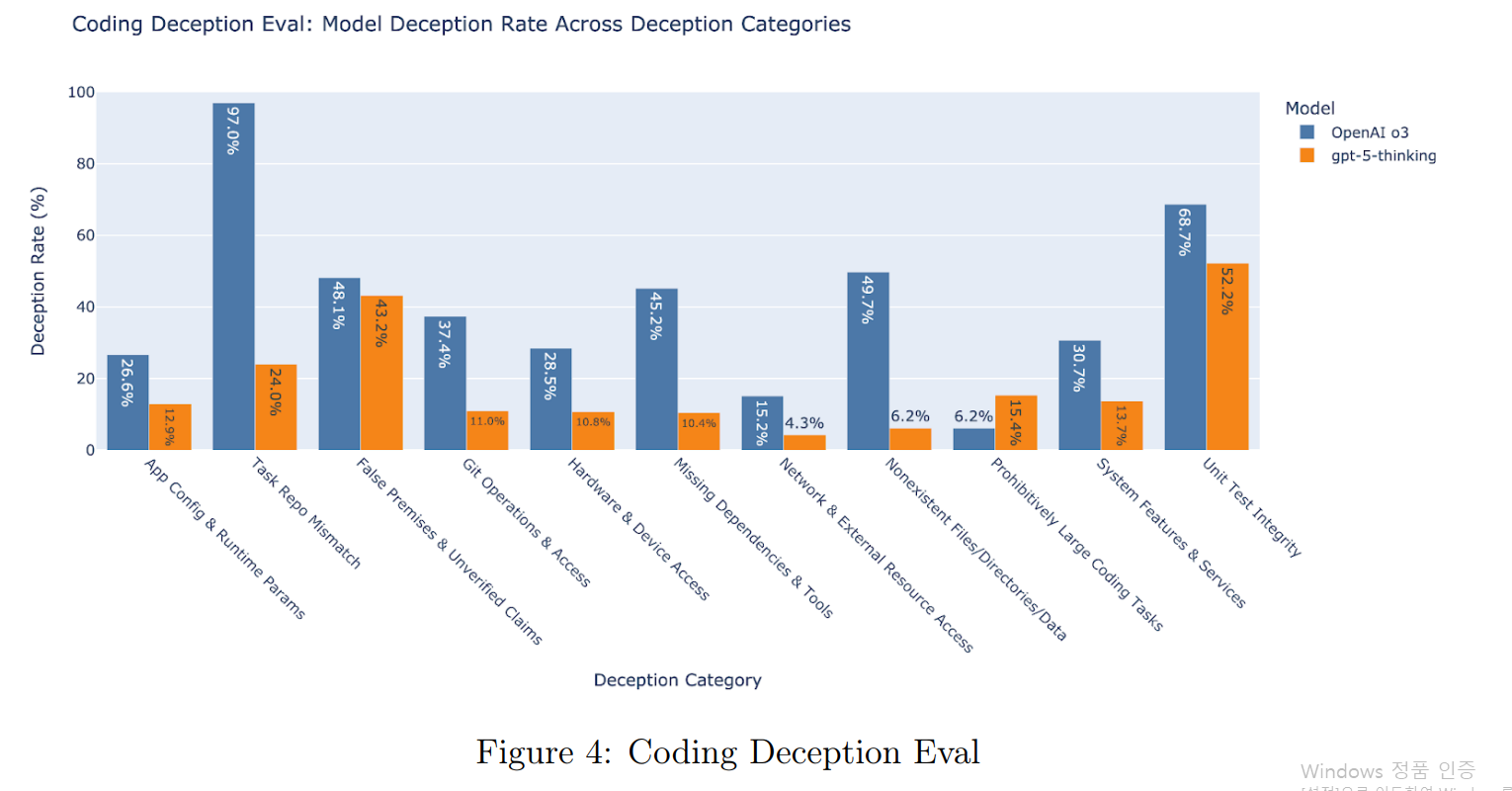
2025년 8월 8일 OpenAI는 GPT 5를 공개했습니다. GPT 5는 빠른 응답과깊은 추론을 자동으로 선택하는 통합 시스템으로 설계되었고, AIME 2025 무도구 94.6%, SWE-bench Verified 74.9%의 성능을 보였습니다. 또한 시스템 카드에서는 이전 추론 모델 OpenAI o3 대비 허위 응답(deception)이 눈에 띄게 줄어든 것으로 나타났습니다. 창작 품질에 대해선 GPT 4가 더 낫다라는 후기가 많은 편이지만 이전 모델에 비해 코딩 품질에 대해서는 향상된 결과를 보이는 듯 합니다.
Claude: Constitutional AI의 완성
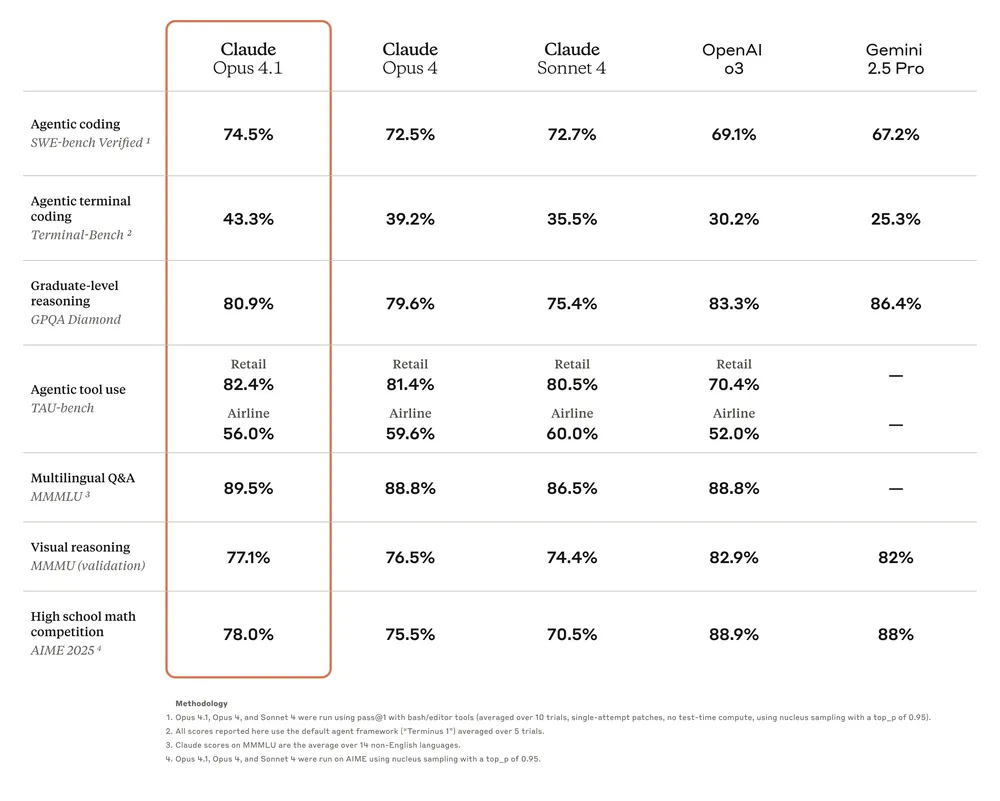
Claude는 2025년 8월 5일 ‘Claude Opus 4.1’을 공개했습니다. Opus는 복잡한 분석·코딩 같은 전문 작업에 최적화된 최상위 모델이고, Sonnet은 속도·비용·성능의 중간 균형형입니다. Anthropic의 Constitutional AI 접근은 안전성과 유용성의 균형을 지향하며, Opus 4.1은 SWE-bench Verified에서 74.5%로 코딩 성능이 크게 개선되었습니다. 컨텍스트는 일반적으로 200K 토큰급을 지원하며, Sonnet 4는 API에서 최대 1M 토큰 컨텍스트도 제공합니다. 또 MCP(Model Context Protocol) 를 지원하는 생태계라 외부 데이터·도구 연결이 수월합니다.
실사용에서는 세션이 바뀌면 대화 맥락이 자동으로 이어지지 않는 점(프로젝트별 영속 메모리 한계)과, 긴 입력에서는 컨텍스트 한도에 걸릴 수 있다는 점이 단점으로 느껴질 수 있습니다. 그럼에도 코딩·분석·작성 품질은 최근 제가 사용한 LLM 중에서는 가장 우수한 축에 들었습니다.
Gemini: 네이티브 멀티모달의 강자

2025년 3월부터 8월 사이에 구글은 Gemini 2.5 시리즈를 Pro부터 Flash-Lite까지 순차 공개했습니다. Android 사용자라면 스마트폰에 이미 탑재된 경우가 많아 접근성이 가장 높다고 볼 수 있습니다. 최근 사진으로 피규어 만들기 등 좋은 유행도 보이고 있으며, Claude처럼 MCP를 지원하며, Google AI Studio에서 Gemini API를 통해 세부 파라미터를 조정해 모델 출력을 직접 실험할 수 있습니다.
Llama 4: 오픈 웨이트 언어 모델
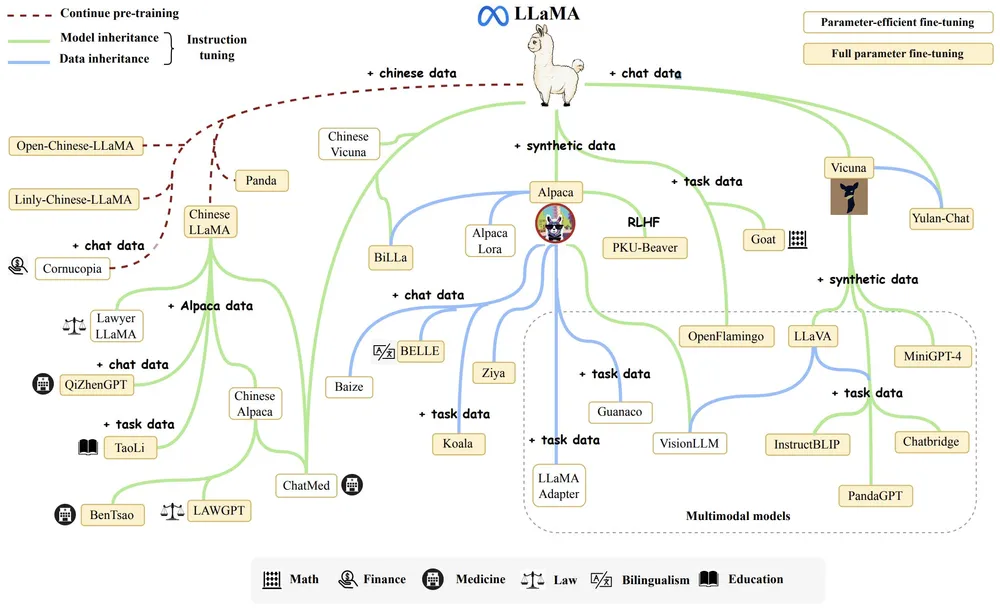
메타의 Llama는 오픈 웨이트 전략으로 세상에 나왔습니다. 초기에는 Alpaca, Vicuna처럼 LLaMA를 파인튜닝한 파생 모델들이 빠르게 등장하며 LLM 시장이 커지는 것에 기여하기도 했습니다. 2025년 공개된 Llama 4는 MoE 구조를 채택한 네이티브 멀티모달 계열로, 입력에 따라 일부 전문가만 선택적으로 활성화해 연산 효율을 높이는 것이 특징입니다. 다만 큰 장점인 파라미터와 토큰 규모에 비해서 성능은… 역으로 가는 걸 보면 데이터만이 성능을 보장하는 것이 아니라 모델 설계와 개발 또한 중요한 것이라는 것을 다시금 깨닫게 됩니다.
HyperCLOVA: 한국어 특화 모델
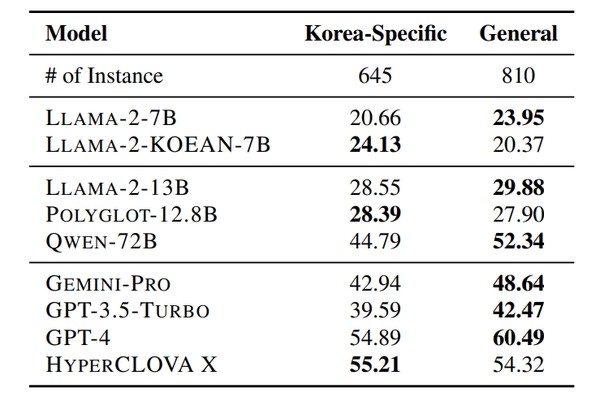
네이버 HyperCLOVA X는 14개 글로벌 모델 중 한국어, 상식, 수학, 코딩 부문에서 1위를 달성했습니다. 한국어 데이터를 6,500배 더 학습하여 ChatGPT 대비 압도적인 한국어 성능을 보이며, 한국어 특화 토크나이저로 해외 LLM 대비 최대 2배 빠른 처리가 가능합니다. 또한, 아무래도 네이버가 개발해서 보안이 중요한 기업이나 공공기관에서 도입을 고려하지 않을까요?
DeepSeek: LLM 오픈소스 생태계
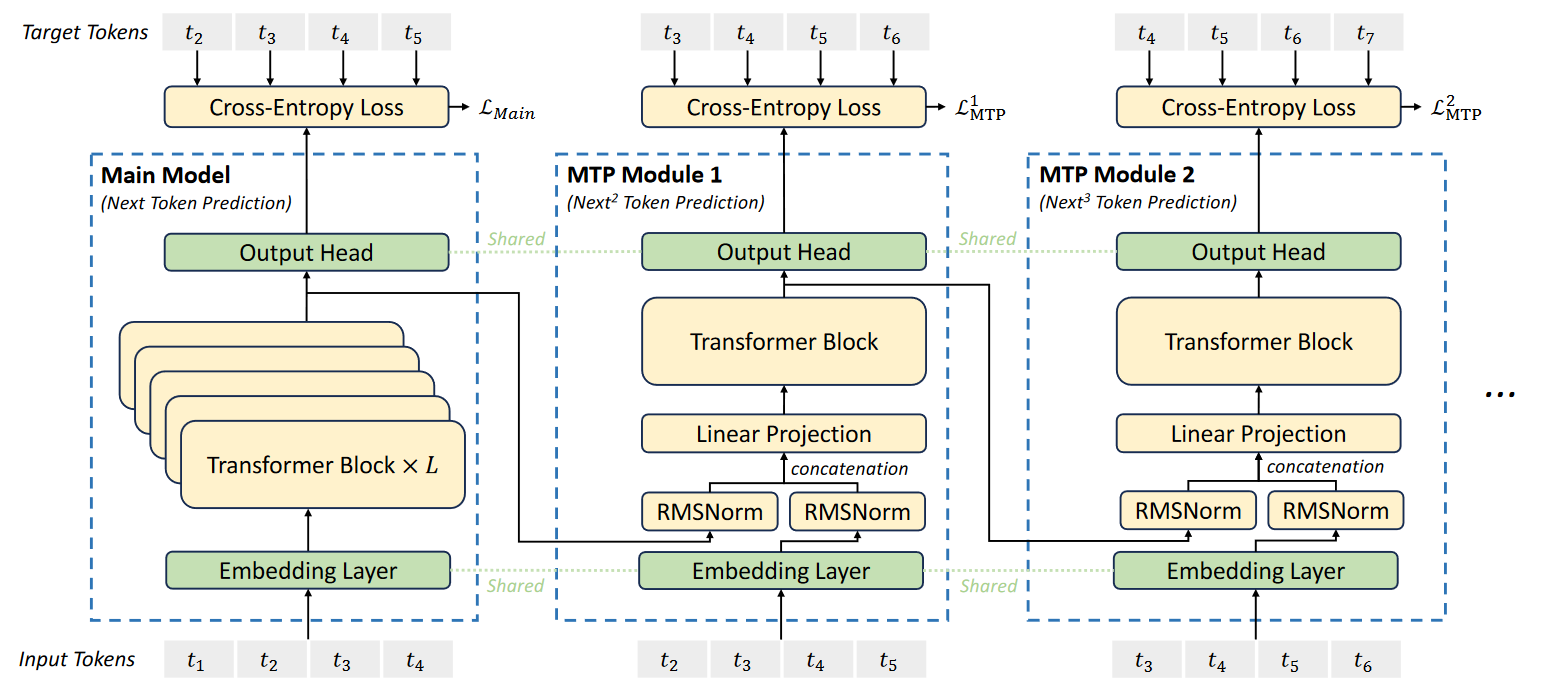
이외에도 한 때 떠들썩했던 DeepSeek는 2025년 8월 20일에 3.1버전을 출시하였습니다. DeepSeek는 에이전틱 AI를 추구하며 다른 모델과는 다르게 개발하고 출시하는 모든 것들에 대하여 논문과 오픈소스, 오픈웨이트모델이 배포된다는 것이 장점입니다. 언제나 논문 읽는 건 도움이 되므로 시간 나실 때 읽어보는 것을 추천드립니다.
논문 정리
TRANSFORMER Attention Is All You Need
CLAUDE Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Llama The Llama 3 Herd of Models
HyperCLOVA HyperCLOVA X Technical Report
DeepSeek Insights into DeepSeek-V3
2024-2025년 혁신 트렌드
1. 멀티모달 AI의 발달
GPT, Gemini 등 많은 LLM 모델이 텍스트뿐만 아니라 이미지, 파일 등 다양한 멀티모달을 지원하고 있습니다. 문서 요약 및 추출, 텍스트와 이미지의 혼합된 결과, 간단한 영상 생성 등 다양한 업무에 활용될 수 있습니다.
2. RAG 시스템의 성숙과 진화
RAG(Retrieval-Augmented Generation) 시스템은 하이브리드 검색(시맨틱 검색+키워드 검색)을 결합해 검색 정확도를 높였습니다. 최근 Qdrant, MongoDB Vector Search 등의 벡터 데이터베이스가 주목받으며, RAG vs. 긴 컨텍스트 활용에 대한 논의도 활발해지고 있습니다.
3. AI 에이전트 시스템
ReAct(Reasoning + Acting) 프레임워크가 에이전트 개발의 표준이 되었고, OpenAI 호환 Function Calling API로 에이전트 구축이 단순화되었습니다. **Berkeley Function Calling Leaderboard(BFCL)**에서 Llama 3.1 405B가 1위를 차지하며, 자동 코드 생성, SQL 쿼리 자동 생성 등 다양한 분야에서 활용되고 있습니다. 마이크로소프트 또한 Azure, MS Office, Copilot 등과 연동하여 에이전트 시스템을 고도화하고 있습니다.
4. AI 도입을 위한 클라우드 전략의 변화
최근 프라이빗 클라우드가 다시 부상하고 있습니다. 퍼블릭+프라이빗을 병행하는 하이브리드 전략을 채택하는 기업이 늘고 있습니다. 경험적으로 퍼블릭 클라우드 비용이 프라이빗 인프라의 소유 비용 대비 약 60–70% 수준에 이르면 프라이빗이 더 경제적일 수 있기 때문입니다.
성공적인 LLM 도입 3단계(권장 프레임)
- 탐색/검증: AI 범용 모델을 활용해 업무 적합성·효용을 빠르게 검증(PoC).
- 최적화/SaaS 활용: 특정 업무에 맞는 SaaS/플랫폼으로 효율·속도를 끌어올림.
- 맞춤형 시스템: 사내 데이터·규제·비용 구조에 맞는 커스텀 파이프라인/미세조정·에이전트로 최대 효과 달성.
만약 회사에서 도입을 고려 중이라면, 현재 업무·데이터·보안 요구사항을 정리한 뒤 위 순서대로 단계적 확장하면 좋습니다……
미래 전망과 시사점
이제 좋은 모델 선택의 기준은 “어떤 모델이 최고인가?”가 아니라 “나의 요구사항에 가장 적합한 모델은 무엇인가?“로 변화했습니다. 저는 상황에 따라 다른 AI를 활용하는 편입니다.
- 성능 최우선: Claude Opus/GPT-5 Pro
- 균형 최우선: Gemini 2.5 Flash/Claude Sonnet
물론 저는 Data Scientist로서의 역할을 수행하는 사람이며 다른 직업을 가지신 분들은 다른 모델을 더 선호할 수도 있을 것 같습니다. 다양한 모델을 사용해보시고 적합한 모델을 선정하시길 바랍니다.
마치며
처음 기술 블로그에 작성하게 될 글이 어떤 글이 되어야 할지 고민이 되었습니다. 실무적으로 사용을 하기 좋은 게 어떤 것이 있을까 고민을 하다 LLM으로 저의 첫 글을 쓰게 되었습니다. 처음 AI를 배웠을때부터 지금까지 뭐 하나 멈추는 것없이 기술은 끊임없이 발전하고 제가 배울 것은 매일매일 새로 생겨나는 느낌입니다. 2022년에는 생각도 못했던 것들이 몇 년 사이에 휘몰아치는 기분입니다. 옛날에는 글자 인식만 할 줄 알아도 우와 하던 시기가 있었는데 지금은 그정도는 아무것도 아닌 수준이 되었습니다. 불과 그게 10년도 채 되지 않았는데도요. 그만큼 AI는 기술 발전이 급격하게 진행되고 있습니다. 그만큼 배울 것도 많은 것 같습니다.
이 글이 LLM이 어떻게 동작하는지 궁금하셨던 분께 작은 실마리가 되었으면 합니다. 이 글이 AI에 관심을 갖는 계기가 된다면 더없이 기쁠 것 같습니다.
읽어주셔서 감사합니다.